Fondecyt 3160182
Efficient GPU Computing in Complex Particle-based Domains
ABSTRACT
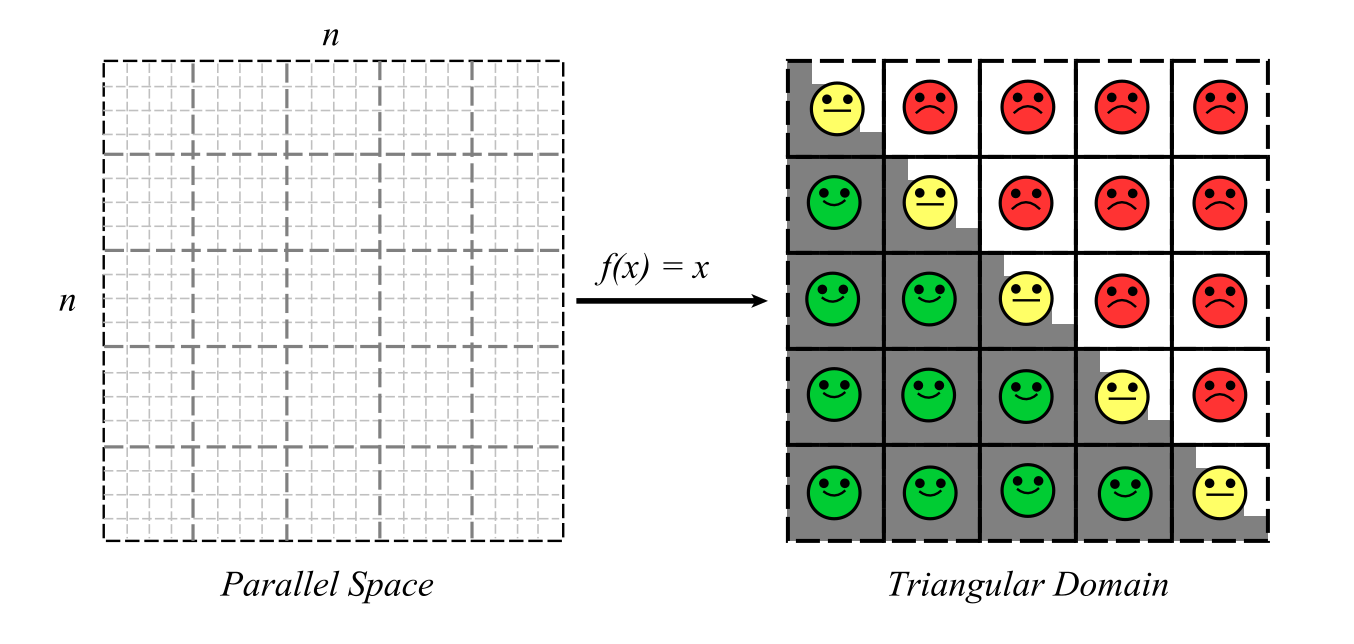
GPU computing has become an important tool for speeding up computational problems that exhibit data-parallelism. Particle-based problems in particular present a large amount of data-parallelism and they are common in many areas of science and technology such as particle simulation, PDEs, cellular automata, molecular dynamics, computing 3D descriptors for shape matching and graph-based problems among others. Solving particle-based problems has proven to be more efficient and convenient with GPU computing, being up to an order of magnitude faster than a CPU-based method. The massive parallelism model, which is an abstrac- tion layer for designing parallel GPU-based algorithms, has been a critical tool for making these algorithms run efficiently and scale properly in the GPU. Its main component is the space of computation, also known as the grid or workspace, which plays an important role for organizing the threads in space and eventually map them to the problem space. In the present, the masive parallelism model works efficiently in box-shaped domains, requiring no special trick for mapping the threads to the problem domain. However, for more complex types of particle-based domains, such as non-square ones, the abstraction presents several inefficiencies at the level of GPU architecture. These inefficiencies can lead to slow performance and disappointing scalability since the parallel processor is not used in the best way. There is a great demand on working with complex domains such as non-rectangular geometries and even fractal ones. To the present day, these types of data-parallel problems present a interesting challenge for GPU computing. This project focuses on researching new techniques for the GPU architecture that can improve the perfor- mance in static and dynamic problems with complex particle-based domains. For the static case, it addresses the problem of achieving the minimum space of computation in complex Euclidean and fractal domains, by proposing mapping functions that preserve locality. The methodology to formulate these maps will be based on the enumeration principle, which is a technique that can provide O(1) cost maps by solving a k -order poly- nomial. For the dynamic case, we address the problem of handling a parallel data structure efficiently in the massive parallelism model. The methodology for the dynamic part is to propose a solution based on a forest of space partitioning trees, instead of one as in the literature, and connect them with an efficient graph such as a Delaunay triangulation. The hypothesis is that it is possible to achieve fast spaces of computation with near- optimal sizes for static domains through map functions. For the dynamic case a forest of trees will increase the data-parallelism leveraging the performance of the GPU. The performance of both solutions will scale as more GPUs are available. The results of this project will have a strong computational impact and applicability, since it is not tied to a single problem, but to a family of problems that share the same properties. Furthermore, these results will eventually help other fields where this type of problems indeed exist, such as computational physics, cellular automata, 3D shape matching and molecular dynamics among others.