Fondecyt 11180881
Exploiting GPU Tensor Cores for Non-Machine Learning Applications
ABSTRACT
The latest advancements in the field of Machine Learning (ML) have not only changed the way many computing problems are solved, but have also influenced the design of computer processors towards the inclusion of application-specific integrated circuits (ASICs) to further accelerate the computations of matrix operations in ML. In the case of Nvidia GPUs, their latest Volta architecture includes a new class of processing units named “Tensor Cores”, which sit in the GPU chip next to the traditional FP32 and FP64 CUDA cores. These tensor cores take parallel machine learning computation one step further, providing up to an order of magnitude of greater performance over the already fast performance of the CUDA cores, making them an accelerator within an accelerator. However, the extra performance offered by the tensor cores does not come without costs; part of the tensor core computation must operate at 16-bit (FP16) and their utilization is not automatic by the GPU, i.e., they have to be manually programmed in a way that is different from the standard CUDA programming model for CUDA cores. The applications that naturally take advantage of tensor core performance are the ones defined by ML theory or linear algebra, more specifically training and inference in deep neural networks and large matrix-multiply operations, which is the purpose why these cores were originally built for. The scenario recently described leads to the formulation of the following two research questions: (1) How can tensor cores be exploited and how much can they further accelerate GPU-based applications that are not naturally defined by ML theory or linear algebra?, (2) Is the tensor core numerical precision still precise enough to guarantee the correctness of the new accelerated applications?. Finding positive answers to these questions would have a great impact in the fields of science and engineering where many problems still require faster solutions.
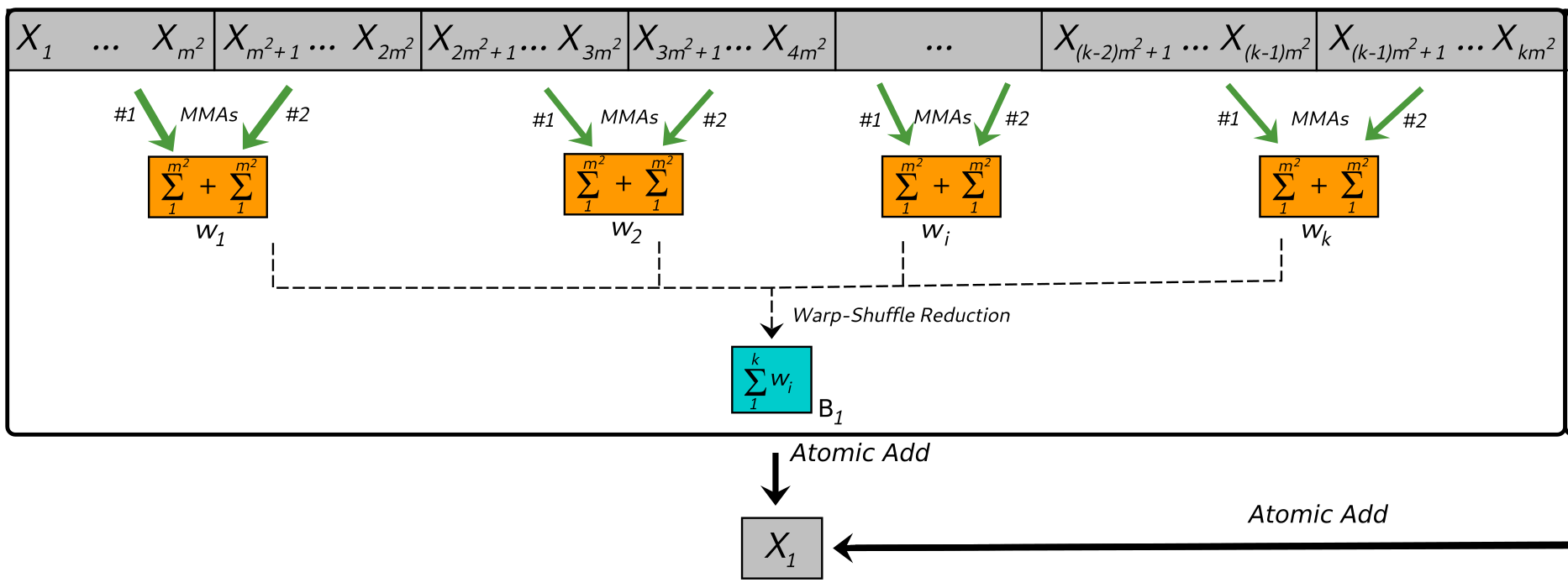
This proposal seeks answers to the research questions presented and sets the goal of finding a way to exploit GPU tensor core performance and accelerate non-ML GPU computing patterns that are frequently used in applications from science and technology. The hypothesis is that GPU tensor cores can further improve the performance of many GPU-based scientific and engineering applications not naturally defined by ML theory or linear algebra. The methodology to conduct this research starts by choosing and re-designing three typically used GPU compute patterns; (1) stencil computations in structured space, (2) interactions of individuals in unstructured space and (3) thread mapping techniques in data-parallel domains with complex geometry. These compute patterns represent several GPU-based application problems from the fields of science and technology that still require faster solutions, such as cellular automata, n-body simulations, the Euclidean distance matrix or efficient GPU-based simulations on embedded fractal domains, among others. The re-design of the compute patterns is based on re-defining the workspace as a set of many parallel matrix-multiply-accumulate (MMA) operations of 16 × 16 matrices, assigning each tensor core computation to groups of threads (warps) which are organized either in columns or single elements in the 16 × 16 matrices. The expected result is a performance improvement for these applications as each tensor core operation takes only one GPU clock cycle. Numerical correctness of the re-designed compute patterns will also be studied in order to report for which range of problem sizes the computations run correct. The importance of these results is not just the speedup on the example applications chosen for testing, but in the fact that the research is conducted at the level of GPU compute patterns, making the results have a wider impact and be useful for families of data-parallel applications who employ these patterns in their solutions.